VAE 기반 추천 시스템 (Variational Autoencoder for Collaborative Filtering) 에서
- x: 유저의 시청 기록 = [1, 0, 0, 1, 1, 0, ...] (영화 클릭 여부 벡터)
- z: 유저의 잠재 성향/임베딩 (ex. 로맨스를 좋아함, 액션은 별로 안 좋아함)
유저가 어떤 잠재 변수를 가졌는 지 알면, 비슷한 분포의 유저에게 같은 영화를 추천해 줄 수 있다! 즉, p(z∣x)를 구해야 한다. 하지만, p(z∣x)를 직접 구하는 것은 매우 어렵다.
p(z∣x)=p(x)p(x,z)인데, p(x)=∫p(x,z)dz p(x)는 intractable
MCMC를 사용하면 해결되긴 하지만, 속도가 너무 느림
posterior 분포 p(z∣x) 를 적당히 근사할 수 있는 분포 q(z)로 대체해서 복잡한 계산을 없애자.
- 여기서 q(z)는 우리가 다루기 쉬운 분포를 사용하자. ex. gaussian, GMM, beta 등
- 분포의 파라미터(ex. μ,σ)를 적당히 바꿔가면서 p(z∣x)랑 가장 유사해지는 분포를 찾자.
q(z)≈p(z∣x)가 되게끔 KL divergence를 최소화하는 방법으로 구할 수 있다.
q∗(z)=argminqKL(q(z)∥p(z∣x))
여기서, ELBO를 최대화 하는 방법으로 KL을 divergence를 최소화 할 수 있다.
KL divergecne의 정의에 의해,
DKL(q(z)∥p(z∣x))=Eq(z)[logp(z∣x)q(z)]=Eq(z)[logq(z)−logp(x,z)+logp(x)]=Eq(z)[logq(z)−logp(x,z)]+logp(x)
따라서,
logp(x)=Eq(z)[logp(x,z)−logq(z)]+DKL(q(z)∥p(z∣x))
logp(x)=L(q)+DKL(q(z)∥p(z∣x))
ELBO는 다시, 다음과 같이 나타낼 수 있다.
L(q)=Eq(z)[logq(z)p(x,z)]
logq(z)p(x,z)=logq(z)p(x∣z)p(z)=logp(x∣z)+logq(z)p(z)
L(q)=Eq(z)[logp(x∣z)+logq(z)p(z)]=Eq(z)[logp(x∣z)]+Eq(z)[logq(z)p(z)]
L(q)=Eq(z)[logp(x∣z)]−DKL(q(z)∥p(z))
첫 번째 항은 “잠재 변수 z가 분포 q(z)를 따른다고 가정할 때, z로부터 x를 설명하는 로그확률의 평균”을 의미한다.
두 번째 항은 **잠재 변수 z**가
인코더 q(z∣x) 에서 너무 “마음대로” 분포를 갖지 않도록
**사전 분포 p(z)**에 가깝게 유도하는 정규화(regularization) 역할을 한다.
-
ELBO 최대화
argmaxqELBO=argmaxqE[logp(x∣z)+logp(z)]−E[logq(z)]
여기서 q는 다변량 함수이다. 변수들 간 correlation이 존재하고 서로 다른 분포의 joint를 구하는 것은 매우 어렵다.
분포간의 correlation을 모두 무시하고, 변수들을 독립적으로 근사하자.
q(z)=∏j=1Jqj(zj)
ELBO=−KL[qj∣exp(Ei=j[logp(x,z)])]+C
따라서, KL divergence를 최대화 하기 위해선,
qj(zj)∝exp(Ei=j[logp(x,z)])
확률 분포로 만들기 위해 아래처럼 **정규화(normalizing constant)**를 붙여준다.
qj(zj)=∫exp(Ei=j[logp(x,z)])dzjexp(Ei=j[logp(x,z)])
각 j에 대해:
- 다른 모든 qi를 고정
- qj만 업데이트
- 1, 2의 과정을 ELBO가 수렴할 때까지 반복한다.
기대값을 계산할 수 없을 때, 샘플링을 통해 근사하는 방법
어떤 확률분포 p(θ) 아래에서, 어떤 함수 f(θ)의 평균을 알고 싶은 상황.
Ep[θ]=∫θ⋅p(θ)dθ 이런 형태의 계산은 머신러닝, 베이지안 추론, 강화학습 등에서 자주 등장한다.
적분 대신 샘플 몇 개 뽑아서 평균을 내자.
Eq(z)[logp(x∣z)]≈L1∑l=1Llogp(x∣z(l)),z(l)∼q(z)
- z를 q(z∣x)에서 샘플링한다.
- 디코더 p(x∣z)에 넣는다.
- log likelihood 계산한다.
- 보통 L=1∼5 정도만 해도 잘 작동한다.
특정 분포를 샘플링 하기 위해서, z∼Uniform(0,1) 의 z를 transformation을 통해 우리가 원하는 분포로 옮겨주자. 원하는 분포 T는 어떻게 찾을 수 있을까?
T(z)=X 가 되도록 하는 T를 찾아보자.
FX(x)=p(X≥x)=p(T(z)≥x)=p(z≥T−1(x))=T−1(x)
FX(x)=T−1(x)
T(x)=FX−1(x)
분포가 복잡할 때, Inverse CDF를 구하기 어렵다는 단점이 있다.
우리가 샘플링하고 싶은 분포:
p(z)=Zp1p~(z)
- p~(z): unnormalized density (비정규화 상태)
- Zp: 정규화 상수 (보통 모름)
- 이런 상황에서는 Rejection Sampling을 사용한다.
Proposal 분포 q(z)와 scaling factor k를 사용해 kq(z)≥p~(z) 가 되는 범위를 덮도록 한다.
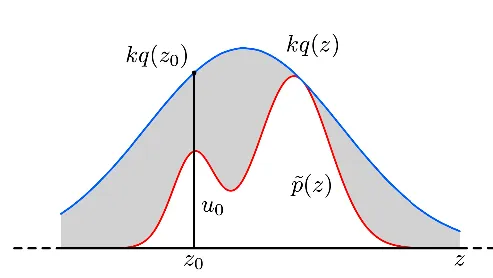
- z0∼q(z) 에서 샘플링
- u0∼Uniform(0,kq(z0)).
- u0≤p~(z0)이면 accept, 아니면 reject
accept될 확률: p(accept)=∫kq(z)p~(z)q(z)dz=k1∫p~(z)dz
p(accept∣z)=∫0p~(z)/kq(z)kq(z)1du=kq(z)p~(z)
q(z)p(accept∣z)=kp~(z)
kp(accept)=∫p~(z)dz=Zp
p(z)=Zpp~(z)=p(accept)q(z)⋅p(accept∣z)
→ rejection sampling을 통해 p(z)에서 제대로 샘플링한 것과 같아진다!
- 단점
- 고차원에서는 k를 매우 크게 잡아야 함
- reject 비율이 커지고, 학습이 느려짐
- → 고차원에선 비효율적이다
기대값이 알고싶을 때 사용, 기대값 근사.
E[f]=∫f(z)p(z)dz→E[f]≈∑l=1Lp(z(l))f(z(l))
E(f)=∫f(z)q(z)p(z)q(z)dz→E[f]≈L1l=1∑Lq(z(l))p(z(l))f(z(l))
proposal q(z) 가정. q(z)에서 sampling
p~(z)와 q~(z)를 통해 구할 수 있다. 상수배 한 비율만 구할 수 있음. rl~=p~(z(l))/q~(z(l))
Variational Inference는 정확한 posterior 샘플링이 불가능함.
rejection sampling, importance sampling은 high-dimensional 문제에서 잘 작동하지 않음.
- proposal distribution q(z)을 설정한다.
- 이전 샘플 z(m)에 기반해 새로운 z(m+1)를 생성한다.
- 이 과정을 반복하면, 생성된 샘플 분포가 posterior p(z∣x)로 수렴한다.
기존 Monte Carlo는 q(z)를 고정하고 샘플링하지만,
MCMC는 q(z)를 매 스텝마다 이동시키며 적응적으로 p(z)를 근사한다.
다음 상태 z(m+1)는 오직 **현재 상태 z(m)**에만 의존한다.
p(z(m+1)∣z(m),z(m−1),…,z(0))=p(z(m+1)∣z(m))
따라서 초기 확률과, 전이 확률만 있으면 모든 샘플을 만들어 낼 수 있다.
즉, p(z)를 stationary distribution으로 갖는 마르코프 체인을 만드는 것이 목표이다.
이 조건을 만족하면 p∗(z)는 stationary 함.
단순한 랜덤 걷기 대신, 물리 기반 운동량 정보를 이용해서 더 효율적으로 샘플링
-
구성 요소
- x: 위치(position), w: 운동량(momentum)
- 총 에너지 함수 (Hamiltonian):
H(x,w)=U(x)+K(w)
-
Hamiltonian Dynamics:
dtdx=∂p∂H,dtdp=−∂x∂H
-
작동 방식
-
무작위 운동량 w0 샘플링
p(w)∝exp(−V(w))
-
Leapfrog 통합법으로 x,w를 시간 단위 ϵ만큼 업데이트
-
MH-style accept/reject
a(x0,w0,xT,wT)=min(1,exp(−H(x0,w0))exp(−H(xT,wT)))
- 에너지가 보존되므로 accept 비율이 높음
- detailed balance 만족 → posterior 수렴 보장