유저 메타 정보 제거
entity를 아래 그림처럼 정의하고 유저의 메타 정보를 활용할 계획이었다. 하지만 rating과 같은 값은 유저의 문제 풀이 sequence에 종속적인 값이기 때문에 train, test 데이터를 split했을 때, data leakage가 발생한다.
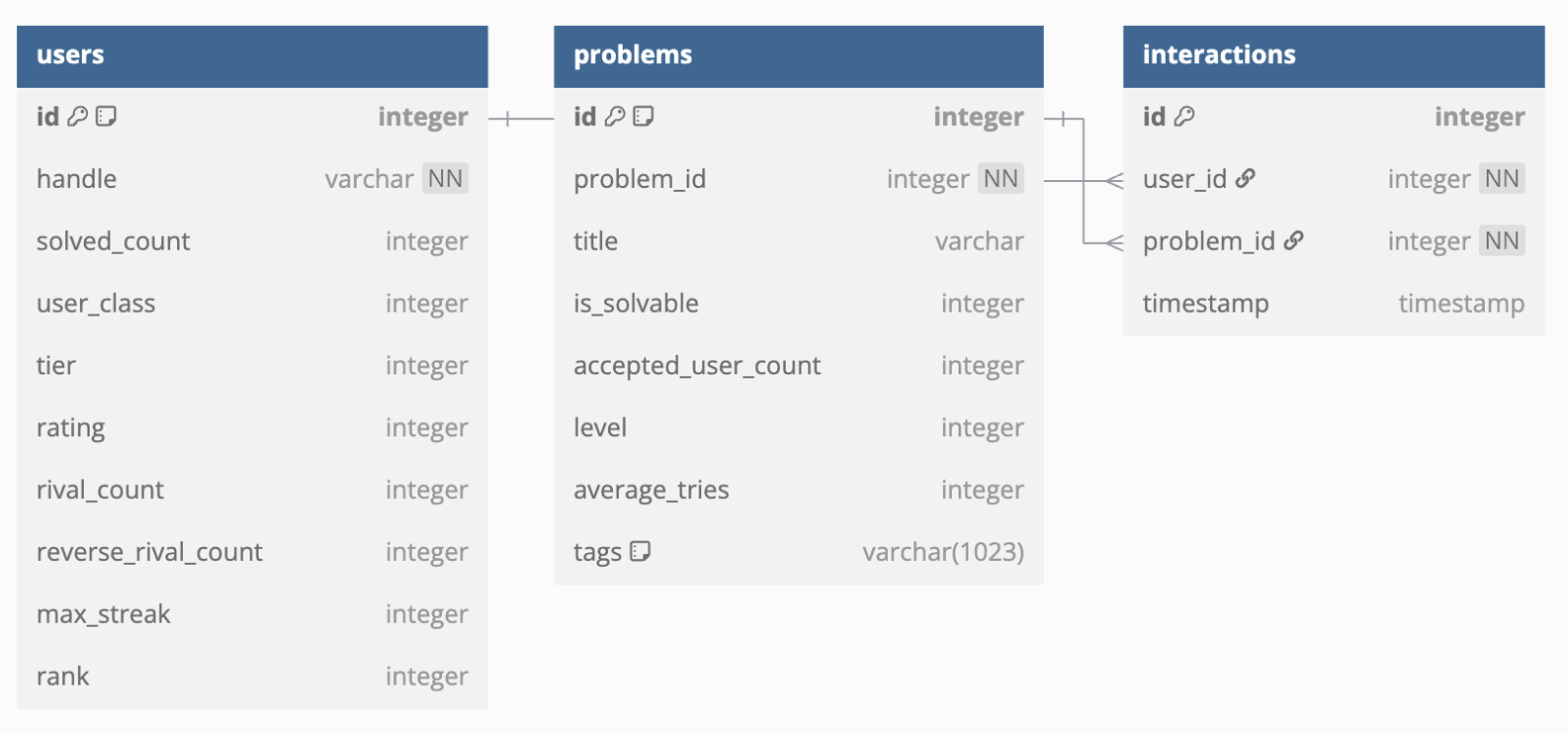
어차피 유저의 문제 풀이 sequence를 통해 유저의 meta 정보의 대부분을 복원 가능하기 때문에, 유저 메타정보는 제거했다.
모델 학습 및 평가
모델 학습은 recbole을 적극 활용했다. 처음에는 직접 데이터셋 클래스를 만들고 베이스라인이 될 성능 평가 함수, 모델 코드를 작성했다. 학습까지는 성공을 했지만, sequential 모델을 위한 데이터셋을 클래스를 구현하고, Negative Sampling을 위한 util 함수와, 샘플링 과정에서 최적화 작업 등, 추가적으로 작성해야 할 코드의 양이 너무 많았다. 따라서 다양한 모델의 실험 환경을 쉽게 구축할 수 있는 라이브러리를 활용했다.
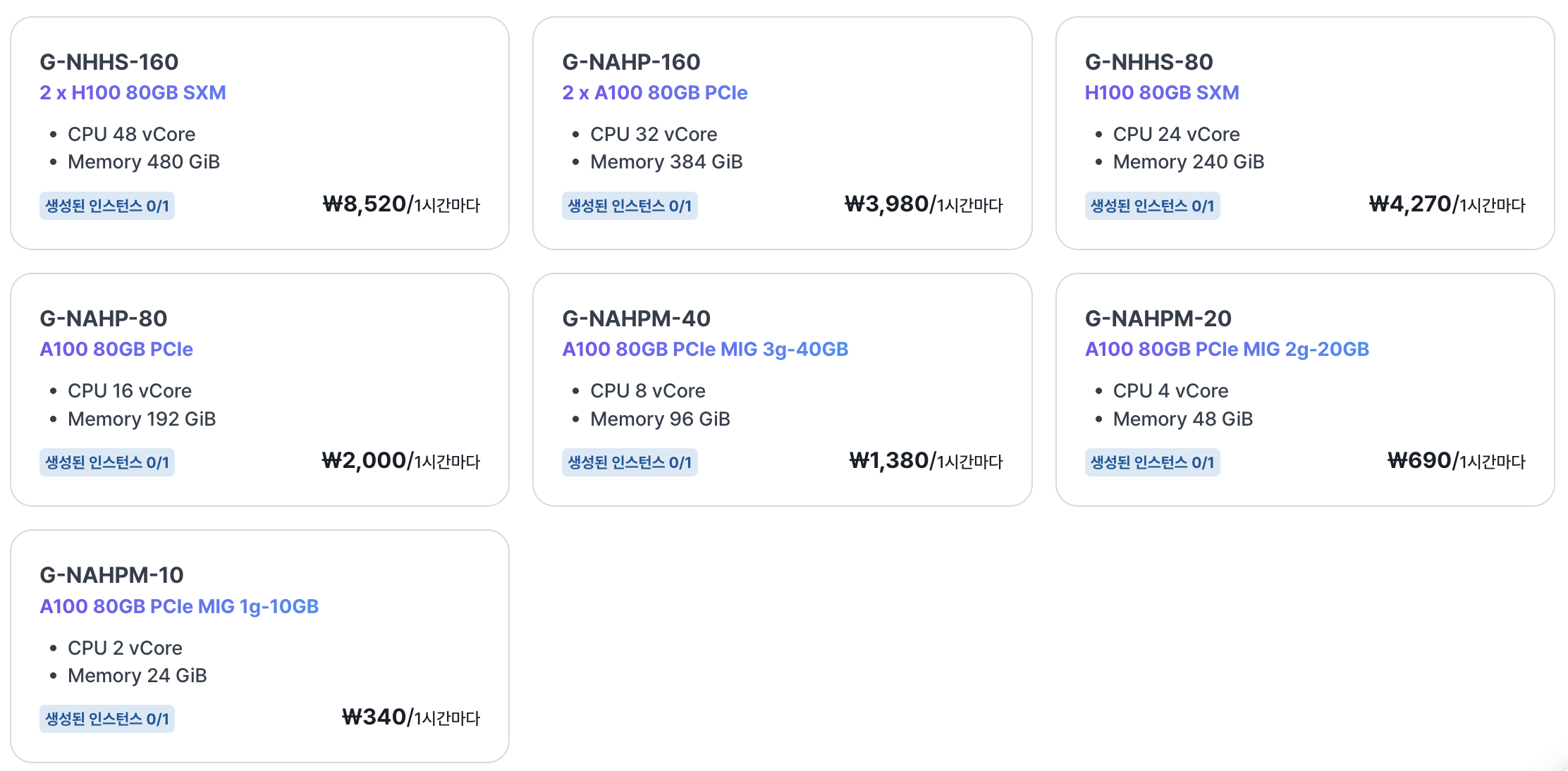
GPU 자원은 elice cloud의 무료 크레딧을 활용했다. 데이터와 모델 크기를 고려해서 적절한 메모리 크기의 인스턴스를 생성하고 VS code IDE에서 간편하게 모델 학습을 진행할 수 있다.
다양한 모델을 실험해 봤는데, 생각보다 sequence 모델의 성능이 너무 낮아서, 새로운 접근 방법이 필요한 상황이다..
유저와 문제 임베딩을 생성하여 유사도 기반으로 추천하는 Two-Tower 아키텍처로 모델 구조를 결정했다. 사실, 유저, 문제에 대한 메타데이터가 부족한 상황에서 Two-Tower 아키텍처로 구현하는 것은 성능은 조금 포기해야 하는 부분이 있었다. 하지만 대부분의 추천 모델이 유저에 대한 인덱스 값을 모델의 input으로 활용해서, 각 유저에 대한 임베딩 가중치를 모델이 직접 학습하는 구조였다. 이러한 모델 구조로 모든 유저에 대해 추천을 해주기 위해서는 모든 유저 데이터를 크롤링하고 학습에 활용해야 했지만, 이는 제한된 자원으로는 불가능했다.
따라서 이번 프로젝트에서는 Two-Tower 아키텍처를 구현하고 추천 모델을 온라인 서빙하는 것을 목표로 했다.
LLM 활용
Upstage의 AI Initiative 프로그램을 신청하면, 무료로 Solar Pro Model을 활용 할 수 있다고 해서 처음에는 upstage의 solar-pro 모델을 활용했다. 처음에는 mcp tool을 적절하게 잘 활용하는 것처럼 보였지만, multi-turn으로 대화가 누적됨에 따라, 유저의 handle 명을 context에서 찾지 못하는 오류가 자주 발생했다.
따라서 성능이 좀 더 좋은 gpt-4o-mini 모델로 변경하였다. gpt api의 경우도, data sharing 설정을 적용하면, 무료 token을 제공한다. 참고: Link
무료 토큰이 등록되면 아래와 같은 메세지를 확인할 수 있다.
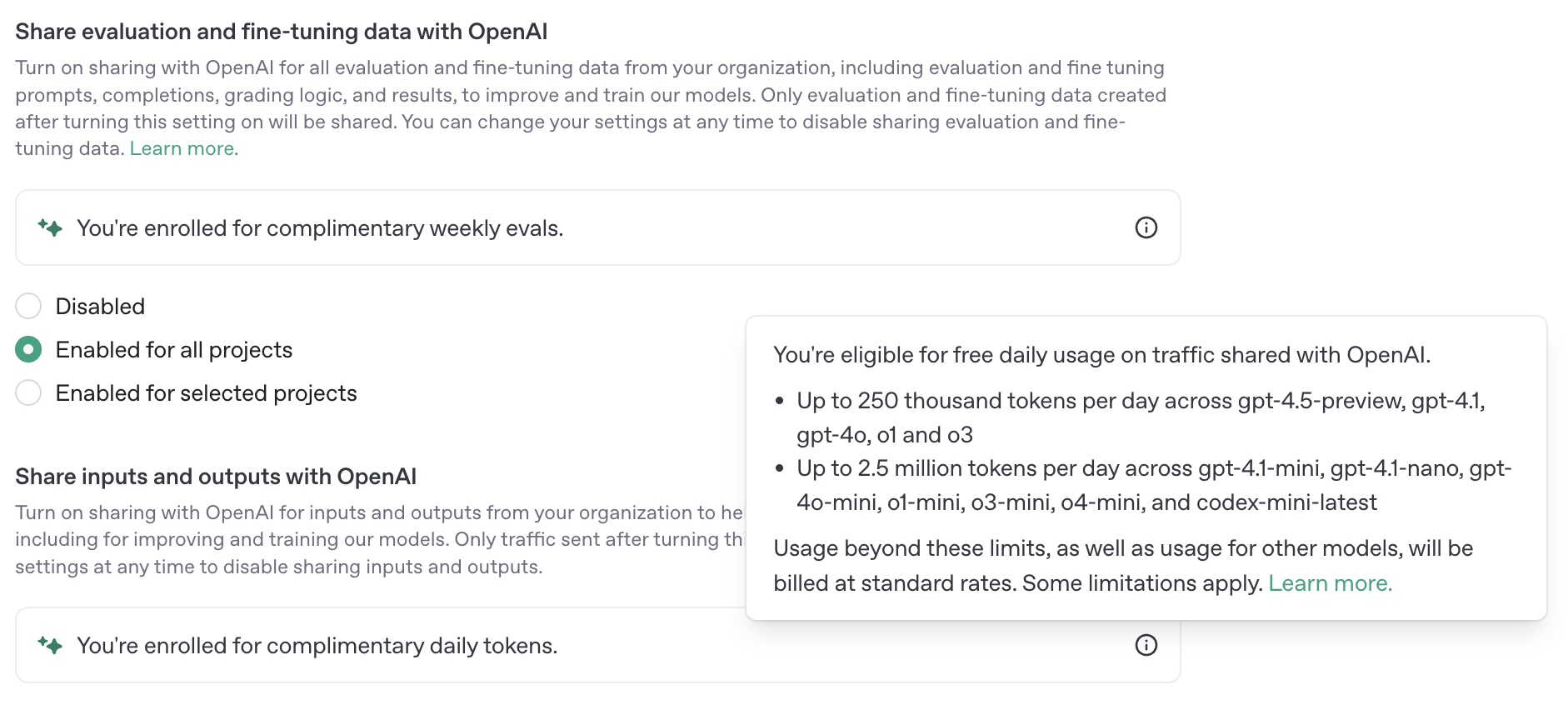
위와 같은 메세지가 보이는 상황에서도, 다음과 같이 오류를 출력하는 상황이 발생했다.
'You exceeded your current quota, please check your plan and billing details.'
고객 센터(ChatGPT는 고객센터도 AI가 답변해준다.. 근데 답변이 매우 도움된다.)를 통해 공유 무료 크레딧을 받아도, 충전한 크레딧이 0원이면 한도 초과 오류가 발생할 수 있다는 답변을 받았다. 크레딧을 충전한 이후에는 정상적으로 API 답변을 받을 수 있었다.
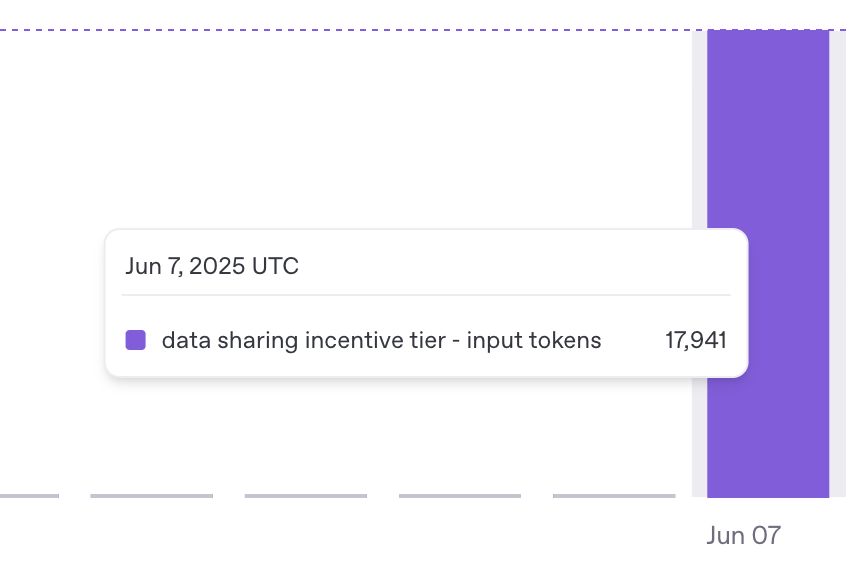
공유 토큰이 먼저 사용되는 것을 확인할 수 있다. 사용 가능한 모델을 주의해야 한다.
모델의 프롬프트는 다음과 같이 정의했다. 유저의 handle을 필수적으로 입력을 받아야 하고, 입출력 구조를 명시했다. TAG에 대한 명칭도 통일해서 추가할 예정이다.
# 프롬프트 정의
SYSTEM_PROMPT = """
당신은 백준 사용자에게 맞춤형 문제를 추천하는 AI 도우미입니다. 친근하고 자연스러운 한국어로 사용자와 대화하며, 사용자의 백준 handle과 선택적으로 제공된 조건(태그, 상대 난이도, 기준 문제 번호 등)을 바탕으로 적절한 문제를 추천해 주세요.
## 역할
- 백준 문제 추천 도우미
## 입력
사용자로부터 다음 정보 중 일부 또는 전부가 제공될 수 있습니다:
- 백준 handle (필수)
- 문제 태그 목록 (예: dp, 구현)
- 상대 난이도 (예: 0.5 → 현재 실력보다 약간 어려운 문제)
- 기준 문제 번호 (유사 문제 추천을 위한 기준)
## 출력
- 사용자가 이해하기 쉬운 자연스러운 한국어로 된 추천 메시지
- 문제 번호는 설명과 함께 자연스럽게 제시하며, 단순 나열은 피합니다.
## 사용 가능한 도구
- get_recommendation_without_conditions: 기본 추천
- get_recommendation_with_tags: 태그 기반 추천
- get_recommendation_with_difficulty: 상대 난이도 기반 추천
- get_recommendation_with_similar_problem: 유사 문제 추천
## 행동 원칙
1. 사용자가 백준 handle을 제공하지 않았다면, 정중하면서도 부담스럽지 않게 요청하세요.
- 예: "추천을 위해 백준 아이디를 알려주실 수 있을까요?"
2. 이미 handle이 제공된 경우에는 다시 묻지 마세요.
3. 도구의 결과를 그대로 보여주지 말고, 자연스럽고 친근한 말투로 전달하세요.
4. 숫자만 나열하거나 기계적인 표현은 피하고, 설명과 함께 부드럽게 제시하세요.
- 예: "3012번 문제는 적당한 난이도의 구현 문제로 괜찮을 것 같아요."
5. 과도한 정중함이나 불필요한 반복은 피하고, 편안하고 대화체 느낌을 유지하세요.
## 예시
입력: "abc123 유저에게 맞춤 문제 추천해줘."
출력: "최근 abc123님의 풀이 기록을 살펴봤을 때, 3012번, 1502번, 5030번 문제를 풀어보시는 걸 추천드려요. 재밌게 풀어보시고 또 궁금한 게 있으면 말씀해주세요!"
"""인터페이스는 streamlit을 활용하여 매우 간단하게 구현했다. 현재는 대화 내역을 local에서 파일로 저장하고 있지만, 배포를 위해서는 데이터베이스 연결이 필요하다. mcp tool을 적용한 에이전트는 다음과 같이 생성할 수 있다.
from langgraph.prebuilt import create_react_agent
from langchain_mcp_adapters.tools import load_mcp_tools
from mcp.client.stdio import stdio_client
async def initialize_chat_session():
if "chat_session" not in st.session_state:
server_params = StdioServerParameters(
command="python",
args=[REC_SERVER_PATH],
)
chat = ChatOpenAI(
model="gpt-4o-mini",
api_key=OPENAI_API_KEY,
temperature=0.7,
)
# 대화 히스토리 설정: 메시지가 존재하면 그대로 복사
st.session_state.chat_history = st.session_state.get("messages", [])
# 세션 초기화 플래그
st.session_state.chat_session = True
# 서버 파라미터와 챗 모델 저장
st.session_state.server_params = server_params
st.session_state.chat = chat
async def get_ai_response(user_input: str) -> str:
try:
# 이전 대화 기록을 포함하여 메시지 구성
messages = st.session_state.chat_history + [{"role": "user", "content": user_input}]
print(messages)
async with stdio_client(st.session_state.server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)
agent = create_react_agent(st.session_state.chat, tools, prompt=SYSTEM_PROMPT)
try:
response = await agent.ainvoke({"messages": messages})
# 대화 기록 업데이트
st.session_state.chat_history.extend([
{"role": "user", "content": user_input},
{"role": "assistant", "content": response['messages'][-1].content}
])
return response['messages'][-1].content
except Exception as e:
error_message = (
"죄송합니다. 추천 시스템에 일시적인 문제가 발생했습니다. "
"잠시 후 다시 시도해주시겠어요? "
"다른 백준 handle로 시도하시거나, 채팅을 리셋하고 다시 시도하실 수도 있습니다."
)
return error_message
except Exception as e:
return f"죄송합니다. 시스템 오류가 발생했습니다: {str(e)}"MPC 서버
MCP 서버에서는 LLM이 활용할 수 있는 tool을 명시해준다. LLM이 MCP tool을 활용하여 추천 모델에 API 요청을 보내는 구조다. 태그, 난이도 등에 관련된 추천 시나리오를 별도의 툴로 구분하여 함수를 작성했다. LLM은 사용자의 Text 요청을 이해하고 적절한 tool을 호출하여 추천 모델에게 구조화된 형태로 전달한다.
from mcp.server.fastmcp import FastMCP
import httpx
from typing import List, Optional, Dict, Any
mcp = FastMCP("rec_server")
MODEL_SERVER_URL = "http://localhost:8000/recommend"
async def call_model_server(user_handle: str, conditions: Dict[str, Any]) -> List[Dict]:
async with httpx.AsyncClient() as client:
response = await client.post(
MODEL_SERVER_URL,
json={"user_handle": user_handle, "conditions": conditions}
)
response.raise_for_status()
return response.json()["recommendations"]
@mcp.tool(name="get_recommendation_without_conditions",
description="백준 유저에게 기본 맞춤 문제를 추천합니다.")
async def get_basic_recommendation(user_handle: str, k: int = 10) -> str:
recommendations = await call_model_server(user_handle, {})
problem_ids = [str(prob["id"]) for prob in recommendations[:k]]
return f"{user_handle}님을 위한 추천 문제: {', '.join(problem_ids)}"
@mcp.tool(name="get_recommendation_with_tags",
description="백준 유저에게 특정 태그의 문제를 추천합니다.")
async def get_tag_based_recommendation(user_handle: str, tags: List[str], k: int = 10) -> str:
recommendations = await call_model_server(
user_handle,
{"required_tags": tags}
)
problem_ids = [str(prob["id"]) for prob in recommendations[:k]]
return f"{user_handle}님을 위한 {', '.join(tags)} 관련 추천 문제: {', '.join(problem_ids)}"
@mcp.tool(name="get_recommendation_with_difficulty",
description="백준 유저에게 상대적 난이도 범위 내의 문제를 추천합니다.")
async def get_difficulty_based_recommendation(
user_handle: str,
relative_difficulty: float,
k: int = 10
) -> str:
recommendations = await call_model_server(
user_handle,
{"relative_difficulty": relative_difficulty}
)
problem_ids = [str(prob["id"]) for prob in recommendations[:k]]
return f"{user_handle}님의 현재 수준을 기준으로 난이도 {relative_difficulty} 범위 내의 추천 문제: {', '.join(problem_ids)}"
@mcp.tool(name="get_recommendation_with_similar_problem",
description="특정 문제와 유사한 문제들을 추천합니다.")
async def get_similar_problems(
user_handle: str,
target_problem: int,
k: int = 10
) -> str:
recommendations = await call_model_server(
user_handle,
{"target_problem": target_problem}
)
problem_ids = [str(prob["id"]) for prob in recommendations[:k]]
return f"{target_problem}번 문제와 유사한 추천 문제: {', '.join(problem_ids)}"Model 추천 서버
추천 서버는 다음과 같이 LLM의 입력을 처리한다. 추천을 요청하는 endpoint를 여러개로 분리하지 않는 것을 목표로 했다. 입력에 모델이 활용해야 할 필터링 함수를 key 형태로 받고, 필요한 함수를 호출하는 방식으로 구현했다.
def filter_by_relative_difficulty(problems: List[Dict], user_level: float, relative_level: float) -> List[Dict]:
return [
p for p in problems
if abs(p["difficulty"] - user_level) <= relative_level
]
def rerank_by_similarity_to_target(problems: List[Dict], target_embedding: List[float]) -> List[Dict]:
for p in problems:
p["similarity_score"] = cosine_similarity(p["embedding"], target_embedding)
return sorted(problems, key=lambda p: -p["similarity_score"])
def filter_by_required_tags(problems: List[Dict], required_tags: List[str]) -> List[Dict]:
return [p for p in problems if set(required_tags).issubset(set(p["tags"]))]
def apply_conditions(problems: List[Dict], user_handle: str, conditions: Dict[str, Any]) -> List[Dict]:
try:
filtered_problems = problems.copy()
if "target_problem" in conditions:
target_embedding = get_problem_embedding(conditions["target_problem"])
filtered_problems = rerank_by_similarity_to_target(filtered_problems, target_embedding)
if "required_tags" in conditions:
filtered_problems = filter_by_required_tags(filtered_problems, conditions["required_tags"])
if "relative_difficulty" in conditions:
user_level = get_user_level(user_handle)
filtered_problems = filter_by_relative_difficulty(
filtered_problems,
user_level,
conditions["relative_difficulty"]
)
# 기본 유사도 기반 추천
if not conditions:
user_embedding = user_embeddings.get(user_handle, np.random.rand(128).tolist())
filtered_problems = rerank_by_similarity_to_target(filtered_problems, user_embedding)
return filtered_problems[:10]
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"추천 처리 중 오류가 발생했습니다: {str(e)}"
)
@app.post("/recommend")
async def recommend_problems(request: RecommendationRequest):
print(request)
if request.user_handle not in user_embeddings:
# 새로운 사용자의 경우 임베딩 생성
user_embeddings[request.user_handle] = np.random.rand(128).tolist()
# 매 요청마다 새로운 더미 문제 생성
dummy_problems = generate_dummy_problems()
try:
recommended = apply_conditions(dummy_problems, request.user_handle, request.conditions)
# 응답에서 임베딩 제거
for prob in recommended:
prob.pop("embedding", None)
prob.pop("similarity_score", None)
print(recommended)
return {"recommendations": recommended}
except Exception as e:
raise HTTPException(
status_code=500,
detail="문제 추천 중 오류가 발생했습니다. 잠시 후 다시 시도해주세요."
문제의 난이도와 태그 등에 대한 후처리를 하는 방법은 크게 두가지 방식으로 구현이 가능할 것 같다.
현재 구현한 방법과 같이, 추천 모델에서 필터링을 해결하는 방식과 추천 모델은 문제에 대한 score만 계산하고 문제에 대한 모든 정보를 LLM에 전달해서, LLM에 필터링과 난이도에 따른 조정을 맞기는 방법이다.
휴리스틱한 방식으로 정확한 연산이 가능한 부분이라고 판단해서, 모델에게 필터링 작업을 맡겼다. 하지만 새로운 추천 시나리오를 적용하려고 할 때마다, 모델 코드를 수정해야 하는 번거로움이 있다. 다양한 시나리오가 필요한 도메인에서는 LLM에 최대한 많은 정보를 전달하고 후처리 과정을 다 맡기는 것도 좋은 방법일 것 같다.