BOJ 추천 프로젝트 (3)
알고리즘 문제 추천에 LLM을 활용해 보고자 하는 취지에서 이 프로젝트를 시작하게 되었다. 하지만, 문제 추천만으로는 LLM의 chat interaction 방식이 효용성이 너무 떨어졌다. 그래서 문제 추천과 더불어, 문제에 대한 설명과 풀이도 제공해 줄 수 있는 기능을 추가했다. 결과적으로 알고리즘 문제 추천에서 알고리즘 학습 도우미로 주제를 수정하게 되었다.
서비스 링크: backjoon-rec
프로젝트 최종 구조
서비스 완성도를 높이기 위해, 기존 Streamlit UI에서, Next.js로 프론트엔드를 바꿨다. 또한 백엔드는 Docker 형식으로 AWS EC2에 올려 서빙했다. 최종 모델은 EASE로 결정했고, 처음 기획했던 Two-Tower 구조 모델 서빙은 기한과 메타 데이터 부족 관계로 포기했다.
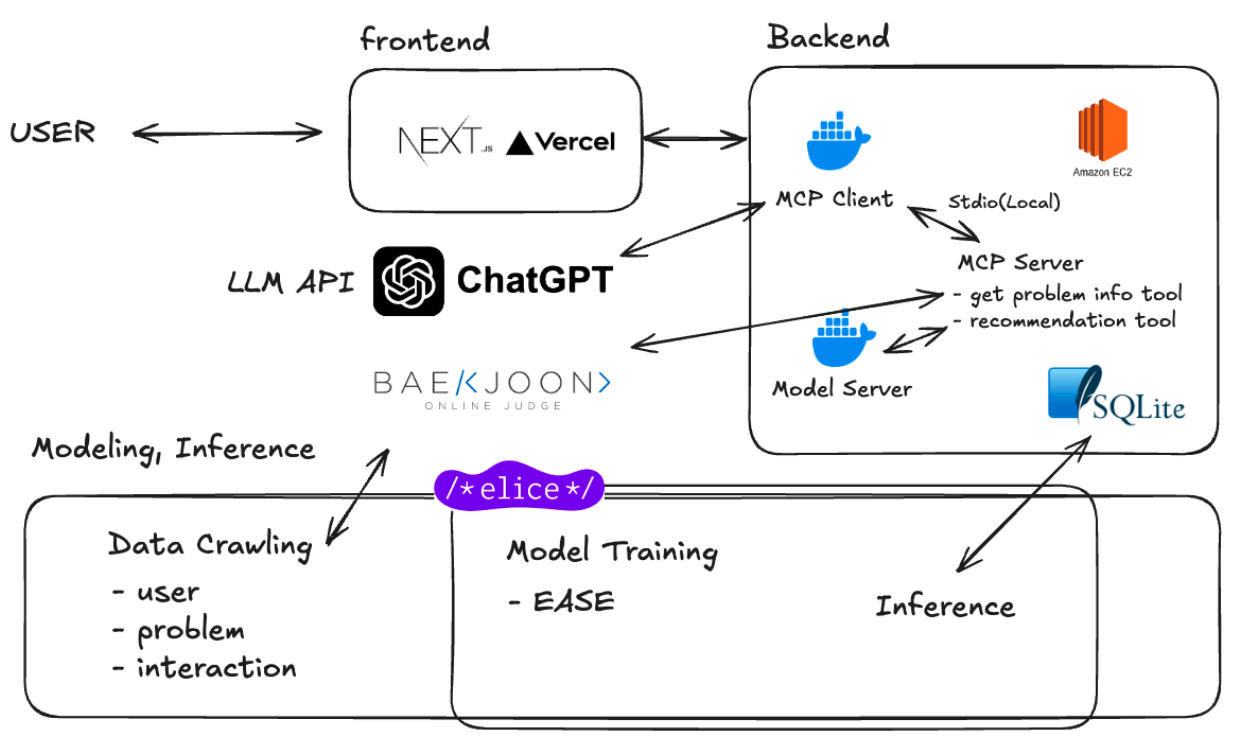
문제 풀이 MCP tool에서만 실시간으로 backjoon 페이지에서 crawling을 진행하고, 모델 학습, 서빙 단계는 오프라인으로 진행된다. DB 관련된 개발은 데모 시연이 가능할 정도로만, 간단하게 SQLite로 개발했다.
결측치 처리
백준에 있는 알고리즘 문제의 난이도는 유저들이 직접 문제에 난이도 기여를 하는 방식으로 산정된다. 이 때, 기여가 부족한 문제는 "난이도 알 수 없음"으로 표시된다. DB 상에서는 이러한 문제들이 level 0 으로 들어 있었고, 결측치 처리를 하지 않으면, level 1보다 더 쉬운 문제로 인식할 가능성이 있었다.
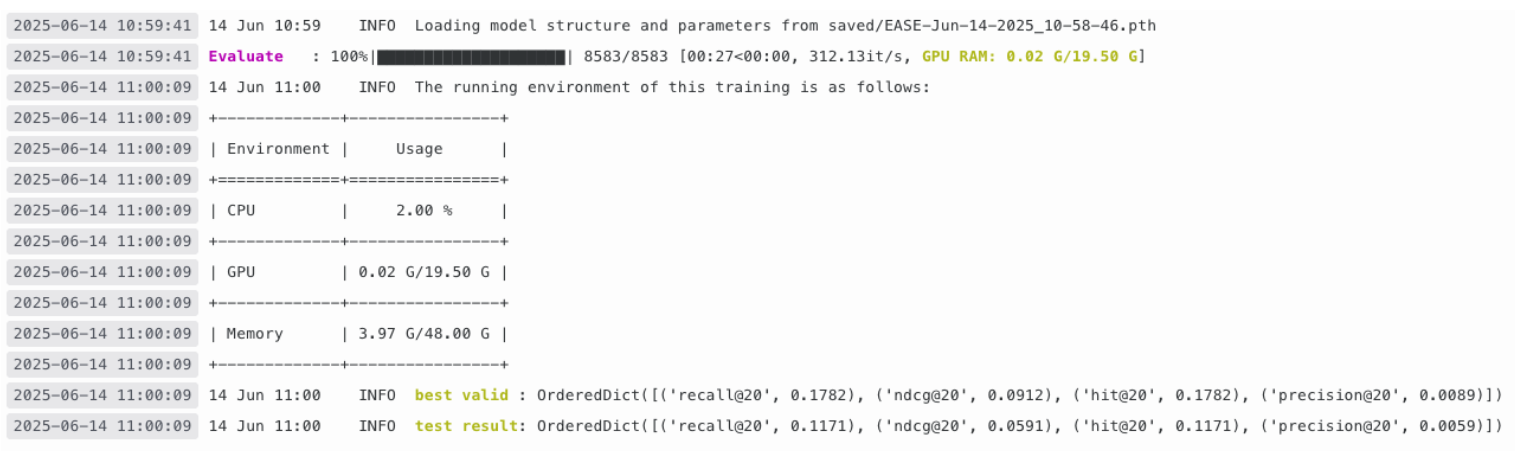
결측치 처리 방법으로는 행 전체를 제거하는 방법을 선택했다. 문제를 푼 유저들의 레벨 평균을 통해 결측치 처리를 진행할까 고민을 했지만, 이러한 남들이 풀지 않을 법한 문제는 대부분 고인물들(레벨이 매우 높은 유저들)이 푼 경우가 많았다. 행 전체를 제거하는 방법이 최선이었다. 결과적으로 문제 수는 32,211개에서 26,171개로, 인터랙션 수는 2,660,015개에서 1,798,102개로 줄었다.
모델 학습
모델 학습에 관련된 부분은 Recbole을 활용했고, GPU는 elice cloud 환경을 활용했다. dataset을 생성하는 코드와, inference를 위한 코드만 작성했다. testset split 방식이나, 모델 하이퍼 파라미터와 같은 다양한 설정들을 yaml 파일로 쉽게 관리할 수 있었다. 또한 모델 실험 결과 추적은 wandb를 활용했다.
서버 구현
서버 구현은 크게 chat server, model server로 구분했다. chat server는 사실상 MCP client와 같은 역할을 하는 서버다.
chat
채팅을 위한 로그인 기능과, 로그인 세션, 채팅 세션, LLM 관련 API를 FastAPI로 구현했다. 이전 대화를 저장하고, 연속적인 대화 흐름을 기억할 수 있게 하기 위해서 채팅 세션을 분리하고, 각 채팅 세션 전체 내용을 LLM의 Input으로 전달했다. 또한 매번 Input message에 유저 handle을 추가하는 방식으로, 개인화 추천을 할 수 있게 구현했다.
async def get_ai_response(user_input: str, chat_history: List[Dict], user_handle: str) -> str:
"""여러 MCP 서버를 동시에 연결하여 사용"""
chat = ChatOpenAI(
model="gpt-4o-mini",
api_key=OPENAI_API_KEY,
temperature=0.7,
)
# 대화 기록 포맷 변환
formatted_history = []
for msg in chat_history:
role = "user" if msg["type"] == "user" else "assistant"
formatted_history.append({"role": role, "content": msg["content"]})
messages = formatted_history + [{"role": "user", "content": f"[{user_handle}] {user_input}"}]MCP 서버와 LLM이 통신하기 위해서는 stdio와 sse 중에 선택이 가능했다. 간단하게 stdio 통신으로 구현했다. 이 방식은 매번 서브 프로세스를 실행해서 standard input, output 방식으로 프로세스 간 통신을 하게 된다. 현재는 MCP 서버를 활용하는 Client가 1개 뿐이라 굳이 MCP 서버를 항상 켜둘 필요가 없다고 판단했다. 하지만, 다양한 클라이언트에서 MCP 서버에 요청을 보낸다면 MCP 서버를 개별적인 Docker 형태로 sse 통신을 하는 것이 좋아보였다. 추가적으로 AsyncExitStack() 이라는 비동기 컨텍스트 관리자 스택을 알게 되었다. 여러개의 비동기 컨텍스트를 한 번에 관리할 수 있었다.
async with AsyncExitStack() as stack:
all_tools = []
# 모든 MCP 서버 연결 설정
for server_name, server_path in MCP_SERVERS.items():
try:
server_params = StdioServerParameters(
command="python",
args=[server_path],
)
# 연결 설정
read, write = await stack.enter_async_context(
stdio_client(server_params)
)
session = await stack.enter_async_context(
ClientSession(read, write)
)
await session.initialize()
tools = await load_mcp_tools(session)
all_tools.extend(tools)
print(f"{server_name} MCP 서버에서 {len(tools)}개 도구 로드")
except Exception as e:
print(f"{server_name} MCP 서버 연결 실패: {str(e)}")
continue
if not all_tools:
return "추천 시스템에 접근할 수 없습니다."
# 모든 도구가 연결된 상태에서 에이전트 실행
agent = create_react_agent(chat, all_tools, prompt=SYSTEM_PROMPT)
response = await agent.ainvoke({"messages": messages})
return response['messages'][-1].contentMCP server
MCP 서버는 FastMCP로 쉽게 구현할 수 있었다. 문제 정보를 가져오는 서버와, 문제 추천 요청을 하는 서버로 구분해서 2개의 MCP server를 구현했다. 문제 정보는 문제에 대한 상세한 설명에 필요한 서버이다. GPT에 문제 해설 요청을 했을 때, 링크에서 상세한 정보를 가져오지 못하는 현상이 있었다. 이를 해결하기 위해 문제의 제목, 설명, 입출력 예시 등을beatifulsoup로 직접 crawling하는 MCP tool을 추가했다.
문제 추천 MCP는 난이도 기반 추천, 태그 기반 추천, 일반 추천 3가지 tool을 제공한다. 난이도 기반 추천에서는 대화의 맥락을 이해하고, 이전에 요구했던 난이도를 고려해서 새로운 난이도로 추천을 제공해야 했다. 난이도 기반 추천의 description으로 아래와 같은 설명을 추가하였다. LLM의 출력에 조절한 난이도를 명시하는 방법을 적용했다. 이를 다음 난이도 조절 요청에 활용하여 맥락을 파악할 수 있게 했다. 결과적으로 "어려운 문제 요청" 후 다시 "어려운 문제 요청"을 했을 때, 이전 추천 문제보다 다음 추천 문제의 난이도가 더 올라가는 것을 확인 할 수 있었다.
@mcp.tool(name="get_recommendation_with_difficulty",
description="""
백준 유저에게 상대적 난이도 범위 내의 문제를 추천합니다.
- `relative_difficulty`는 -10 ~ 10 사이의 정수로, -10은 가장 쉬운 문제, 10은 가장 어려운 문제를 의미합니다.
- 사용자의 난이도 요청이 반복되면, 이전 추천보다 더 어려운(또는 더 쉬운) 문제를 추천하기 위해 누적적으로 가중치를 조절할 수 있습니다.
- 일반적으로는 한번에 1~3 정도의 난이도 변화가 적절하지만, 문맥상 '더 어려운', '훨씬 더 어려운' 등의 요청이 있다면 더 크게 조정할 수 있습니다.
- 응답에는 사용된 가중치 값을 반드시 명시해주세요. 예: (난이도 조절: +6)
""")
태그 기반 필터링은 모델의 요청에서 명시한 tag명과 DB에 존재하는 tag명이 동일해야 한다. 그렇기 때문에 자주 등장하는 tag 기준으로 상위 46 태그를 사용 가능 태그 목록으로 전달했다.
@mcp.tool(name="get_recommendation_with_tags",
description="백준 유저에게 특정 태그의 문제를 추천합니다. 제외할 태그도 선택 가능합니다. 사용 가능 태그 목록: math, implementation, dp, graphs, data_structures, greedy, string, bruteforcing, graph_traversal, sorting, ad_hoc, geometry, trees, number_theory, segtree, binary_search, constructive, simulation, arithmetic, set, prefix_sum, bfs, combinatorics, case_work, dfs, shortest_path, bitmask, hash_set, dijkstra, backtracking, sweeping, disjoint_set, tree_set, parsing, dp_tree, priority_queue, divide_and_conquer, two_pointer, game_theory, parametric_search, stack, probability, primality_test, flow, lazyprop, dp_bitfield")
async def get_tag_based_recommendation(user_handle: str, tags: List[str], excluded_tags: List[str] = [], k: int = 10) -> str:
recommendations = await call_model_server(
user_handle,
{"required_tags": tags, "excluded_tags": excluded_tags}
)
problem_ids = [str(prob["id"]) for prob in recommendations[:k]]
return f"{user_handle}님을 위한 {', '.join(tags)} 관련 추천 문제: {', '.join(problem_ids)}, 제외 태그: {', '.join(excluded_tags)}"model
모델 서버는 구성이 간단하다. 오프라인 배치 서빙 방식을 선택했기 때문에, DB에서 user handle로 조건을 걸어서, 유사도 상위 k개의 문제를 추천하면 된다. 필터링을 고려하여, 100개의 문제를 먼저 DB에서 가져온다. 그 이후 추가적으로 난이도와 태그에 대한 조건이 존재하면, 필터링함수를 호출한다.
@app.post("/recommend")
async def recommend_problems(request: RecommendationRequest):
"""사용자에게 문제 추천"""
try:
# 사용자 ID 조회
user_id = get_user_id_from_handle(request.user_handle)
if user_id is None:
raise HTTPException(
status_code=404,
detail=f"사용자 '{request.user_handle}'를 찾을 수 없습니다."
)
# DB에서 추천 결과 조회
recommendations = get_user_recommendations_from_db(user_id, top_k=100)
if not recommendations:
raise HTTPException(
status_code=404,
detail=f"사용자 '{request.user_handle}'에 대한 추천 결과가 없습니다."
)
# 조건에 따라 필터링
if request.conditions:
recommendations = apply_conditions(recommendations, request.conditions, request.user_handle)
final_recommendations = recommendations[:request.top_k]
return {
"user_handle": request.user_handle,
"total_found": len(recommendations),
"returned": len(final_recommendations),
"recommendations": final_recommendations
}난이도 필터링은 아래와 같이 Sliding Window 방식으로 구현했다.
# 난이도 필터링
def filter_by_difficulty_range(problems: List[Dict], relative_difficulty: int, user_handle: str) -> List[Dict]:
"""난이도 범위로 필터링"""
filtered = problems
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute('SELECT level FROM users WHERE handle = ?', (user_handle,))
user_level = cursor.fetchone()[0]
conn.close()
print(f"user_handle: {user_handle}, level: {user_level}")
if relative_difficulty is not None:
min_level = int(user_level - 2 + relative_difficulty)
max_level = int(user_level + 2 + relative_difficulty)
if min_level < 0:
min_level = 0
max_level = 4
if max_level > 30:
max_level = 30
min_level = 26
filtered = [p for p in filtered if p["difficulty"] >= min_level and p["difficulty"] <= max_level]
return filteredFront 구현
프론트엔드는 cursor의 도움을 받아, 빠르게 구현했다. ChatGPT의 UI를 참고하여, 초기 화면에서는 가운데에 Input Text 박스를 배치했다.
이후에 채팅을 입력하면, 새로운 채팅 세션이 생성되고, Input Text 박스가 아래쪽에 배치되게 된다.
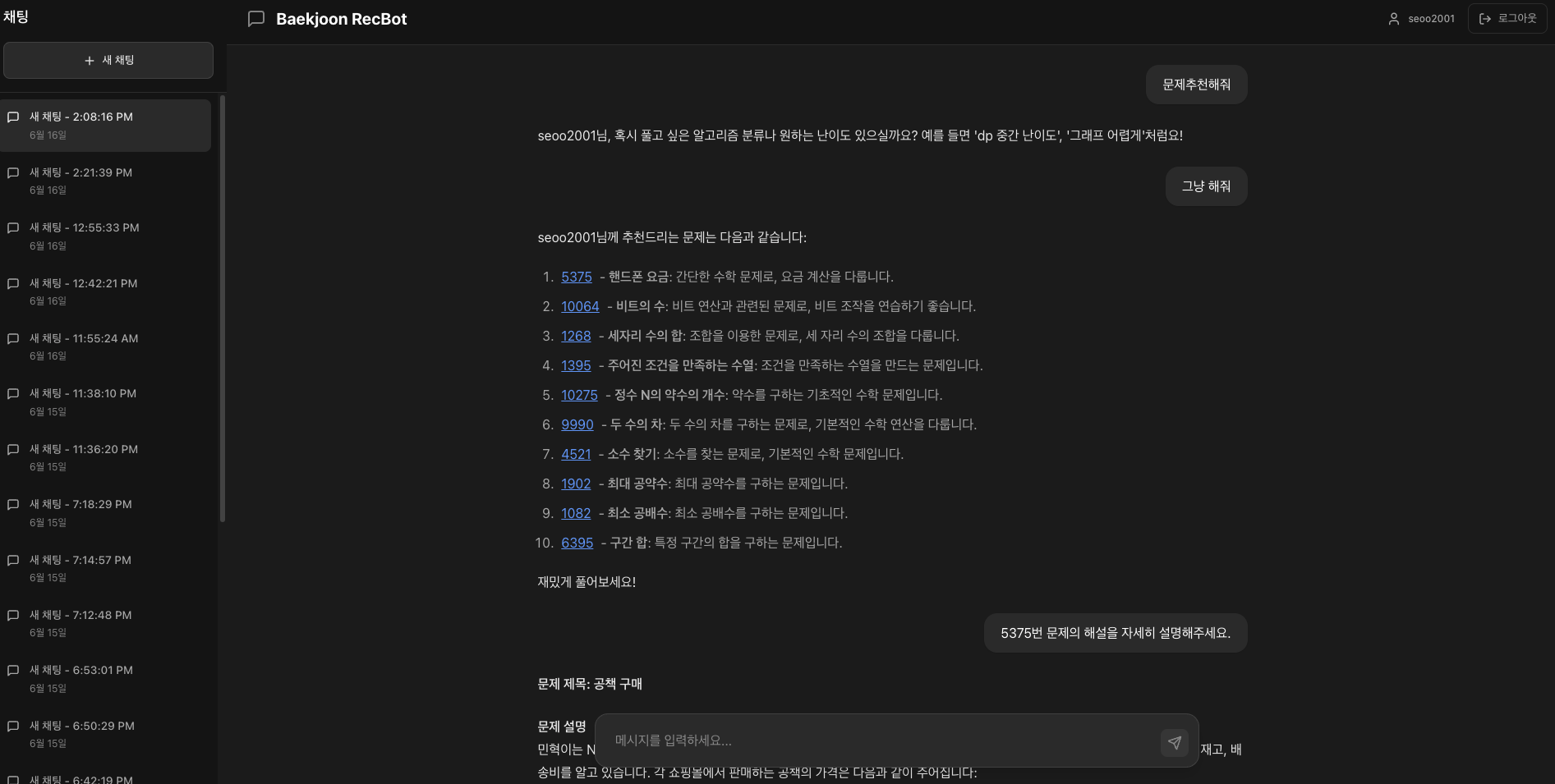
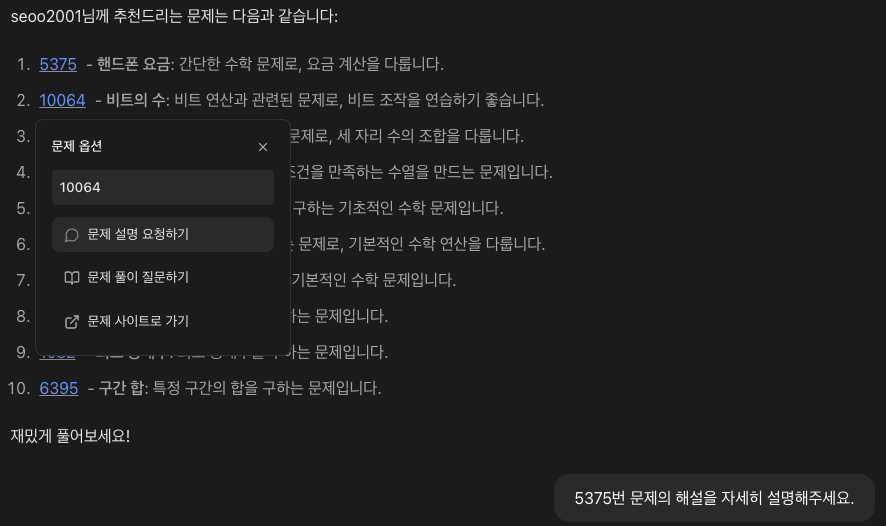
추천받은 문제의 ID를 클릭하면 아래와 같이, 문제 아래에 Modal이 생성된다. 선택한 문제에 대한 해설이나 풀이 요청, 웹 페이지 이동이 가능하다.
GPT 모델의 출력이 Markdown 형식을 따르기 때문에, react-markdown을 활용하여, 가독성을 높였다.

회고
모델 부분에서 좀 더 깊게 고민을 해 볼 수 있는 여지가 많았던 것 같은데, 단순하게 EASE 모델을 학습하고 오프라인 배치 서빙 방식을 선택한 게 아쉬웠다. 이 프로젝트를 통해 온라인 서빙을 경험하고자 하는 것이 가장 큰 목표였는데, 생각보다 모델의 성능이 너무 낮았다.
문제 추천을 다른 도메인의 추천과 구분할 필요가 있었다. CF 기반 추천이 문제 추천에는 딱히 의미가 없어 보였다. "다음에 풀 문제 예측"은 "다음에 구입할 물건 예측"과 매우 다른 문제였다. 또한 다음에 풀 문제를 잘 예측하는 것이, 좋은 알고리즘 문제 추천인가에 대한 문제도 존재했다. "유저의 실력 향상에 가장 도움이 되는 문제"를 추천하는 것이 좋은 추천이라고 생각했지만, 이를 위한 실험과 모델을 설계하기가 어려웠다.